Technology assisted review is a powerful tool for controlling review costs and workflows. But, to maximize the benefits of TAR, we must be able to understand the results.
Predictive coding has, for years, promised to reduce the time and expense of increasingly large scale litigation reviews. For attorneys and project managers assessing different methodologies, it has been challenging to understand what evaluative metrics are relevant. F-scores are often inappropriately interpreted as measures of review quality when evaluating predictive coding results. But to get a better understanding of how an application of predictive coding has performed and to manage the defensibility of your review, the component elements of the f-score – precision and recall – should be reviewed. But how do precision and recall scores relate? And, more importantly, what do these results tell you about your production?
In the context of TAR and predictive coding, precision is a measure of how often an algorithm accurately predicts a document to be responsive. In other words, what percentage of the produced documents are actually responsive. A low precision score tells us that there were many documents produced that were not actually responsive, potentially an indication of over-delivery. A high precision score on its own doesn’t mean much, either. One could deliver just 10 documents to opposing counsel, and if all 10 were responsive, we would have 100% precision but we would have almost certainly failed to deliver a very significant percentage of the responsive documents in the collection.
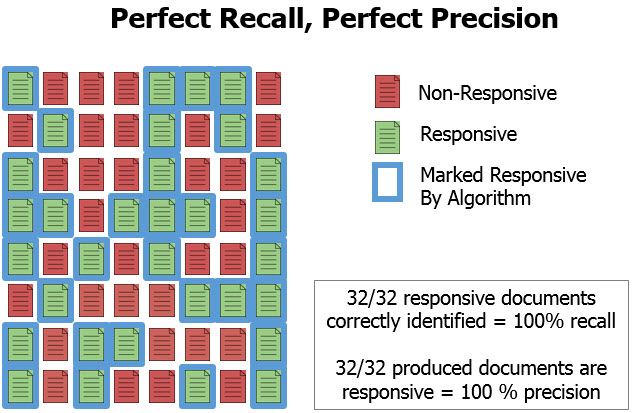
To give our precision score any context relative to the over-riding goal of predictive coding — to quickly and defensibly deliver responsive documents to opposing counsel — we need to look at recall. Recall is a measure of what percentage of the responsive documents in a data set have been classified correctly by the TAR/predictive coding algorithm. When recall is 100%, the algorithm has correctly identified all of the responsive documents in a collection. A low recall score indicates that the algorithm has incorrectly marked responsive documents as non-responsive.

To get an idea of how a predictive coding application has performed we need to look at precision and recall relative to each other. Due to the fundamental limitations of predictive coding technology, it would be very difficult to ever achieve perfect precision and recall on a collection. There is ultimately going to be a trade-off between optimizing the two measures. To improve precision, that is to reduce the proportion of false positives, we are likely going to reduce true positives — recall — as well. Similarly, to improve recall, or reduce the proportion of false negatives, we are likely going to increase the percentage of false positives and negatively affect precision. Because of this interrelation, much of what can be understood about TAR results is obscured by just looking at the f-score and accepting the result if it exceeds some arbitrary measure. Evaluating precision and recall in relation to each other tells a much more detailed story about TAR results.
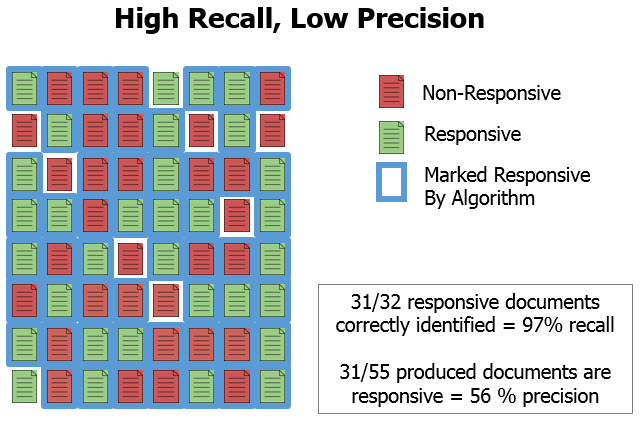
Given what we know about recall scores, it may occur that predictive coding actually gives us an explicit measure of how many responsive documents we didn’t deliver. How can we look at predictive coding results that indicate 80% recall and not be entirely focused on the 20% of responsive documents that haven’t been produced? The answer is that 80% recall may be a far better result than if a massively more expensive manual review of the documents was performed, instead. Though this seems controversial, it is a notion shared by The Sedona Conference, TREC legal track, and the judges who have been approving TAR use.
