How your eDiscovery platform parses and organizes your electronically stored evidence can be the difference between finding or missing that smoking gun. Or worse, unwittingly handing a smoking gun to opposing counsel. Pulling back the curtain on how an eDiscovery platform ingests electronically stored documents and makes the text within documents searchable reveals hidden places where evidence may be hiding. This article explains indexing and breaks down the types of search indexes used in eDiscovery software platforms, discusses the pros and cons of each, and offers solutions to ensure that you never miss crucial evidence.
Indexing occurs during the upload of your documents to your eDiscovery review platform. A number of processes run which separates and organizes your data. The text, in particular, is extracted from your documents and filtered into a database or index. When you enter a search query your software does not review each document searching for the word; that could take hours or days. Rather your software refers to the index (just as you would in a textbook) in order to quickly pull the relevant documents for your review. The process by which the text is extracted from your documents to be placed into that index is critical to the quality of search results.
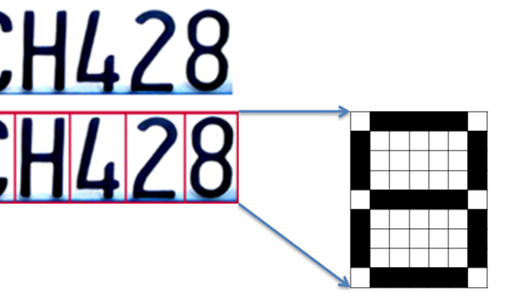
There are 2 basic indexes used in eDiscovery software platforms, an OCR Index or a Text-based (also called Native extraction) Index.
OCR stands for Optical Character Recognition. In this process, your electronically stored documents could be originally scanned or saved from a native document through a virtual print driver. Specialty OCR software recognizes alpha-numeric text patterns. For example, a Word doc uploaded would be “printed” within the software engine and the text that appears on that virtual print would be lifted off the page and indexed.
Text-based Indexing is also called Native Extraction Indexing because instead of processing the document as a printed page it rather looks at all of the underlying code and data within a document. Where OCR sees the document as a print, Text-based indexing lifts the hood and extracts all of the computer-embedded text in a file and additionally will capture the data that you do not see, such as comments.
The pros of one indexing approach are the cons of the other and vice versa. Specifically, an OCR-based index may miss hidden fields, such as hidden columns on an Excel spreadsheet, while a text-based index would not. Conversely, a Native extraction-based index will not read (index) the text on an image, including scanned or PDF’d documents, where an OCR index will.
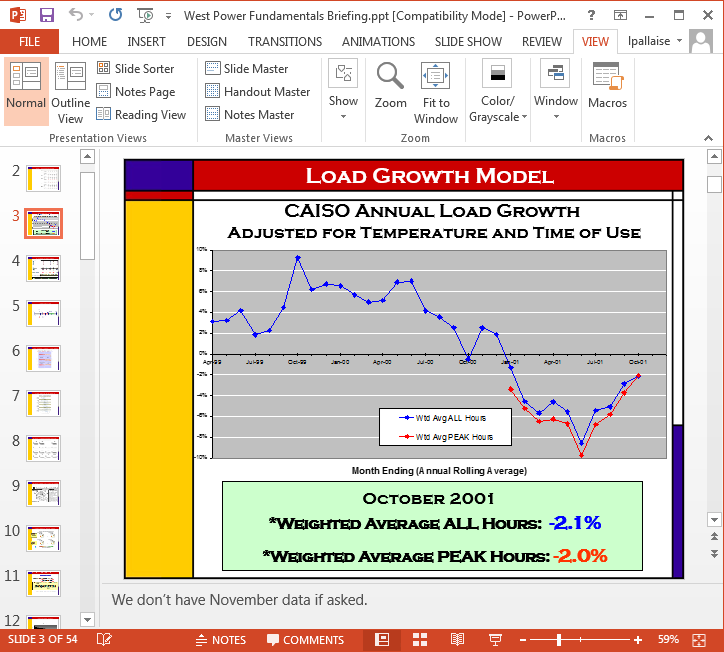
This is an example of a native PowerPoint document. When you receive this doc as a .ppt file an OCR-based index would create a virtual print of each slide and lift any text that appears on that print for indexing. The embedded images with text, like this chart titled “Load Growth Model”, would have all text that appears on the chart indexed. Speaker notes, however, like this one regarding “November Data”, could be missed as notes do not normally show on a print, by default.
Conversely, a native extraction-based index would only recognize the .jpg title of the image of the chart and index that file name as text. It cannot “read” an image (as OCR can) and so none of the text appearing on the chart would be indexed. It would, however, pick up the speaker notes regarding November Data. When you search for the company name “CAISO” an OCR-based Index would retrieve this document but a Native Extraction-based index would not. When you search for “November Data” the Native Index would retrieve this document, but an OCR index would miss it. If you were to perform a Boolean search for “CAISO AND November Data” neither index alone would return this document as responsive as it would only see one term or the other.
Some modern eDiscovery software providers will offer both indexes, however, they are siloed and so you would have to run your entire search twice, once through each index. This not only doubles your search time but still leaves you vulnerable to miss evidence when you are using Boolean searches to narrow results. Some eDiscovery vendors will instruct you to write additional language into your ESI order in an attempt to mitigate the loss of potential evidence. Unfortunately, the more complex an ESI request the more likely that mistakes will be made and evidence missed.
Lexbe has solved this false ‘index dilemma’ by creating the first concatenated eDiscovery search index, our Uber-Index℠. At ingestion, documents are run through both OCR and Native extraction indexing simultaneously. Then the OCR and Native-Extracted indices are compiled into one single, searchable database. All text is captured by these two complementary processes, and all evidence is searchable.
Additionally, Lexbe offers an integrated translation feature which is also included in our Uber Index for seamless search in either language. Whether you opt for Lexbe to perform your document translation or upload your own translated docs, our software will tie the original doc to the English translated one for integrated search and document review.
Finally, Lexbe also performs an advanced metadata extraction at ingestion for precision searches. Details such as the author of a document are extracted and will be searchable.
| Features | OCR Index | Text-Based Index | Lexbe Uber Index |
|---|---|---|---|
| Embedded Text | ✅ | ✘ | ✅ |
| Charts | ✅ | ✘ | ✅ |
| Budgets | ✅ | ✘ | ✅ |
| Scanned Docs | ✅ | ✘ | ✅ |
| Hidden Cells/Sheets | ✘ | ✅ | ✅ |
| Comments | ✘ | ✅ | ✅ |
| Tracked Changes | ✘ | ✅ | ✅ |
| BCC Field | ✘ | ✅ | ✅ |
| Meta-Data Extraction | ✘ | ✘ | ✅ |
| Translated Text | ✘ | ✘ | ✅ |
With the Lexbe eDiscovery platform, your search is faster and more complete than with any other index on the market. For more information on how indexing works watch our webinar Best Practices to Avoid Missing Evidence in Large Document Reviews, part of the Lexbe eDiscovery Webinar Series.
